
Time is money. When a server is down, its owner loses profit. Modern businesses cannot afford server downtime, even for a few minutes, because it negatively affects their competitiveness. This is why most server solutions today are based on fault tolerant systems.
Fault tolerant clustering is the process of combining multiple servers into a group or cluster. If one of the servers fails, its tasks are redistributed to other parts of the cluster. In addition to eliminating the threat of unexpected failure, failover systems are useful when you need to shut down one of the servers for maintenance or other routine work.
In this article, we will discuss failover and fault tolerance in general, which will improve your server operations in the future.
What is Fault Tolerance?
Fault tolerance is the ability of a system to continue operating despite the failure of one or more of its components. A fault tolerant system uses redundant components to ensure that the system continues to function at all times.
Fault tolerance is necessary for any system that has high reliability requirements, such as a banking system or a telecommunications network. By using certain techniques, fault tolerant systems can minimize the risk of downtime and data loss.
Main Principles of Fault Tolerant Systems
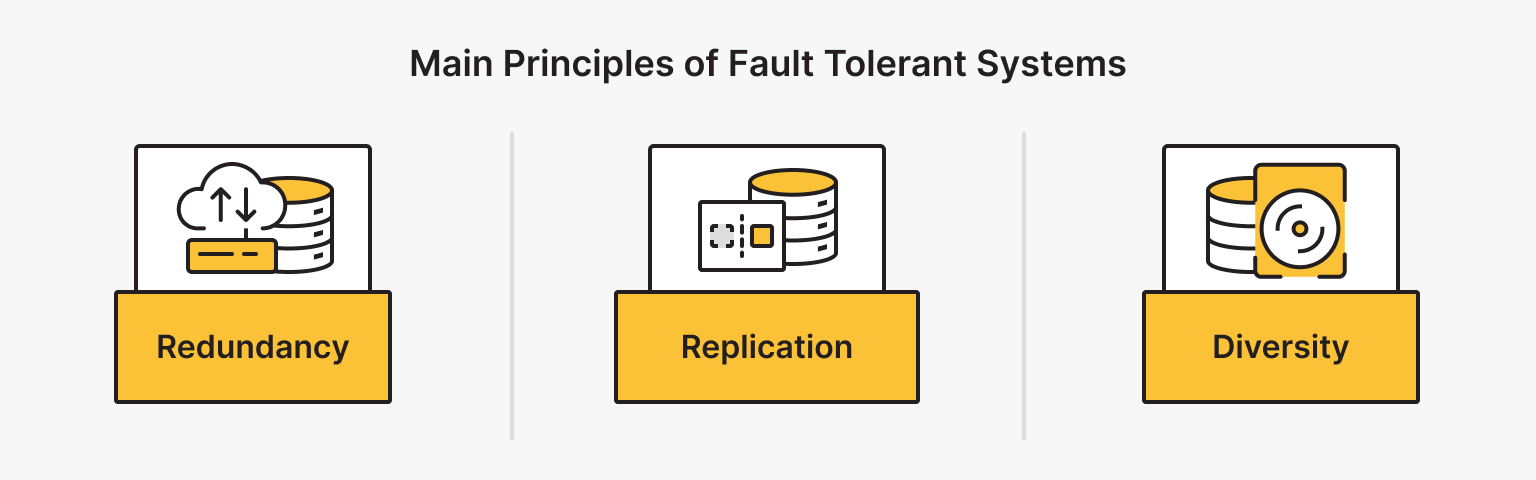
Fault tolerant systems can ensure high availability and resilience only by following certain principles, which allow critical systems to continue operating and minimize downtime. A high level of reliability can be achieved by following these specific principles:
- Redundancy. This refers to having multiple instances of critical components such as servers, storage devices, and network connections. If one component fails, redundant components can keep the system running.
- Replication. This involves copying data to multiple locations. If one copy of data is lost, the data can be recovered from another copy.
- Diversity. This is the use of different types of components in a system. For example, a system might use both solid state drives (SSDs) and hard disk drives (HDDs). If the SSDs fail, the system can continue using the HDDs.
Because of all of these features, fault tolerance involves complex systems that require an integrated approach to both the design and the content of the system.
Types of Fault Tolerant Systems
Fault tolerance of the system can be achieved both by creating redundant server components and by creating a system of servers that can replace each other. In other words, there are two types of fault tolerant systems according to the level of redundancy:
- Server node level redundancy. This type of fault tolerance involves duplicating critical components within a single server node. For example, a server node might have two power supplies, two network cards, and two hard drives. If one of these components fails, the server node can continue to operate using the redundant component.
- Server redundancy. This type of fault tolerance uses multiple servers to create a fault tolerant cluster. If one server node in the cluster fails, the other server nodes can take over its workload.
Server node-level redundancy is less expensive and less complex than clustering. However, providing fault tolerance at the server node level can give less availability than server redundancy (clustering). The best choice of type of fault tolerant system for an application or project depends on the specific requirements.
Fault Tolerance vs High Availability
High availability and fault tolerance are not the same concept.
High availability refers to a system design that aims to minimize downtime, regardless of the cause. Fault tolerant systems, on the other hand, can continue to operate even if a certain number of faults occur.
High availability uses multiple redundant elements and control systems to activate and coordinate them. And fault tolerance uses multiple redundant elements and control systems to make them all work together.
Having a fault tolerant system does not necessarily mean having a highly available system, and vice versa. However, high availability and fault tolerance go well together to create reliable systems and services.
What is a Fault Tolerant Cluster?
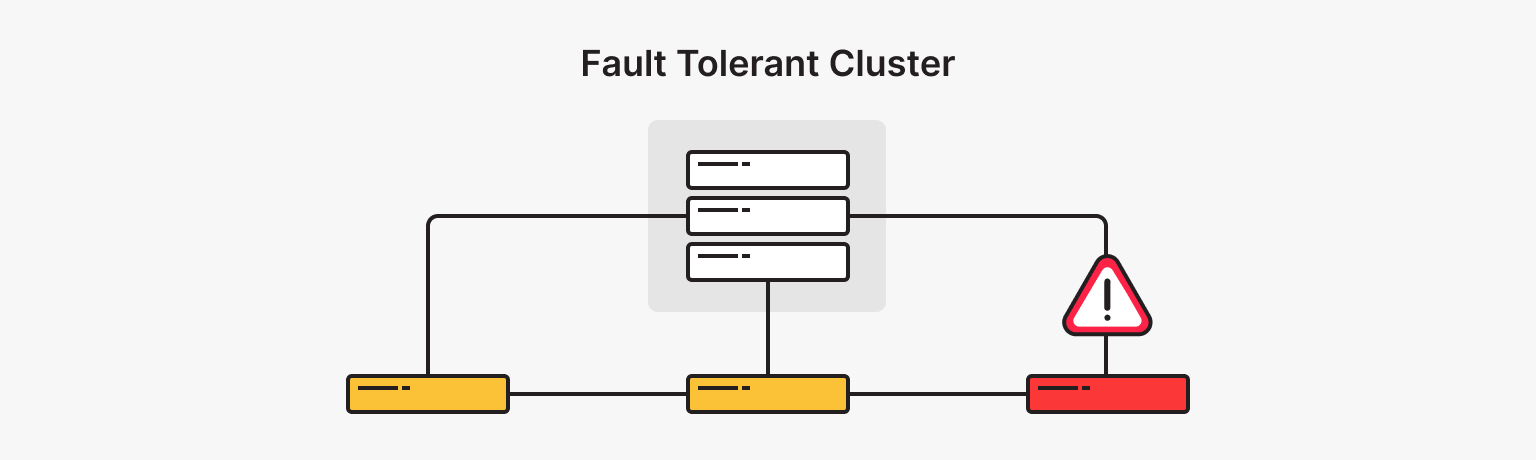
In a fault tolerant system, multiple nodes work together to share the workload and perform tasks. If one node or component fails, the cluster must detect the failure and automatically transfer the workload of the failed node to other functioning nodes to ensure uninterrupted operation. It is this ability to withstand and recover from failures that makes a system fault tolerant.
Fault tolerance is achieved through a combination of hardware redundancy, software mechanisms, and system architecture. This involves eliminating single points of failure with redundant hardware components such as servers, power supplies, and network connections, as well as distributing and replicating tasks across multiple nodes with software techniques such as load balancing, data replication, and automatic failover mechanisms.
However, even with a fault tolerant cluster in your arsenal, you must not forget about other mandatory techniques to protect your data and the entire infrastructure.
Fault tolerance and disaster recovery are two concepts that are inextricably linked. When working with a group of servers, it is essential to maintain the ability to resume operations after a service interruption.
The same goes for backups, which are never a bad thing when it comes to data. By making copies of critical information, you can provide yourself with a safety cushion that will save you from having to do it all over again, or even from losing profits.
Basic Schemes for Building Fault Tolerant Clusters

There are a number of basic schemes for building fault tolerant clusters, each of which varies in terms of application complexity and load balancing:
- Active/passive
All calculations are performed on the main server, and the duplicate server is activated in the event of a failure on the main server. This configuration is expensive because each node is duplicated.
- Active/active
The load of a disconnected server is distributed among other active nodes, which must be identical in terms of both software and hardware. This provides higher availability than an active/passive cluster, but is more complex and expensive to manage.
- A+A
Each server node has its own dedicated storage. This provides even higher availability than a traditional active/active cluster, but is more complex and expensive to manage.
- A+1
A cluster has an active server node and a passive server node. The active server node handles the entire workload and the passive server node is used for failover. However, the passive server node can also be used to handle a portion of the workload. When it completes its task, it reverts to standby status.
- A+B
This is a variation of the A+1 clustering scheme in which the passive server node is not designated for failover. Instead, it can be used for any purpose, such as running batch jobs or providing additional capacity.
It is important to note that the choice of configuration depends on specific requirements, scalability, budget constraints, and desired levels of fault tolerance.
What Do You Need to Build Fault Tolerant Clusters?

To create fault tolerant systems (clusters), you will need a few key components:
- Surplus performance.
This means having multiple copies of each critical component, such as servers, storage devices, and network connections. Free capacity is needed to redistribute tasks to other servers, and in a cluster, the maximum load must be less than the available resources. For example, if there are 12 servers in a cluster, the load cannot exceed the operating capacity of 11 of them. This allows the tasks of a disconnected node to be redistributed without losing capacity. Server performance monitoring remains an important task.
- Shared access to data from each node.
Without this, it is impossible to organize a fault tolerant cluster; if one server fails, tasks must be immediately distributed among the others. At the same time, it is necessary to provide exactly the same (or a backup) channel to the database and to the end users.
- Software compliance.
It is necessary to consider the possibility of using applications in fault tolerant clusters as early as the application development stage. Applications must be able to work with a common distributed data store and restart on another node in the state they were in at the time of the failure, thus disconnecting the server within the cluster.
- Load balancing.
By using some methods to distribute the workload across multiple servers or resources, the performance and reliability of the entire fault tolerant system can be greatly improved. In a fault tolerant cluster, load balancing is necessary to ensure that no server is overloaded and fails.
- Horizontal scaling.
Horizontal scaling increases the capacity of a system by adding more servers or resources. In a fault tolerant cluster, horizontal scaling can be used to improve performance and reliability by adding more nodes to the cluster.
We'll talk more about balancing and scaling, which are last on the list but just as important as the other components.
Load Balancing

Load balancing can work in parallel with fault tolerant clustering. When using a large number of servers, it is important to distribute tasks so that all nodes are roughly equally loaded. Otherwise, some will be overloaded and unable to handle the flow of tasks, while others will be idle.
Static Load Balancing
Static load balancing assigns a fixed number of requests to each server in a fault tolerant cluster, providing a simple method of load balancing.
Static balancing algorithms:
- Round robin balancing. Traffic is distributed to servers one at a time using the Domain Name System (DNS). An authoritative name server maintains a list of different A records for a domain and provides a different record in response to each DNS request.
- Weighted rotation. An administrator can assign a different weight to each server. Servers that are considered to be able to handle more traffic are given slightly more weight. Weights can be configured in DNS records.
- IP hash. The algorithm combines the source and destination IP addresses of incoming traffic and converts them into a hash using a mathematical function. Based on the hash, the connection is assigned to a specific server.
Static balancing is easy to implement, but can be inefficient if the workload is not evenly distributed across servers.
The ideal solution for large-scale projects. Impeccable protection, high performance and flexible settings.
Dynamic Load Balancing
Dynamic load balancing is a more sophisticated method of load balancing that takes into account the current load on each server in the cluster and distributes requests accordingly.
Dynamic load balancing algorithms:
- Least connections. This algorithm checks which servers currently have the fewest connections and routes traffic to those servers. It assumes that all connections require approximately the same amount of processing power.
- Weighted least connection. Allows administrators to assign different weights to each server, assuming that some servers can handle more connections than others.
- Weighted response time. Each server's response time is averaged and combined with the number of active connections on each server to determine where to direct traffic. By directing traffic to the servers with the fastest response times, the algorithm provides a faster user experience.
- Resource-based. The algorithm distributes load based on the resources currently available to each server.
Dynamic load balancing is more efficient than static load balancing, but it is also more complex to implement, which should be considered when building fault tolerant systems.
Horizontal Scaling of the File Server

Deploying a fault tolerant cluster is more complicated when dealing with open or constantly changing files. To avoid disconnecting nodes, a horizontally scalable file server (SOFS, Scale-Out File Server) is used. If it fails, the cluster remains fully functional.
SOFS provides highly available file storage for applications and general use, and is particularly well suited for Hyper-V storage. Scalable file nodes allow you to share the same folder and file across multiple cluster nodes.
SOFS Features
File shares are active-active, meaning that all nodes in the cluster can accept and serve client requests.
The throughput, or performance, of SOFS-enabled file shares is linearly related to the number of nodes added to the cluster. You can increase throughput by simply adding nodes to the cluster.
You do not need to create multiple clustered file servers with separate cluster disks and then develop placement policies. It is sufficient to create SOFS and then add CSVs and file shares.
However, SOFS is not suitable for all workloads. It is best suited for Hyper-V and SQL application data. Shared file I/O, like normal general-purpose end-user file actions, is not well suited for synchronous writing to SOFS.
RAID Fault Tolerance
RAID (Redundant Array of Independent Disks) is a storage technology that uses multiple disks to improve performance and reliability. The RAID system can be used to create fault tolerant storage that can withstand the failure of one or more disks.
RAID uses disk mirroring and striping techniques. Mirroring copies identical data to multiple disks, while striping helps spread data across multiple disks.
We can say that a fault tolerant RAID system is a kind of redundancy at the server node level, because it is specific to the storage system. Since using a large number of disks increases the average time between system failures, redundant storage increases fault tolerance.
While backups serve as insurance but take a long time to restore, RAID bails you out and provides the data you need if one or more disks fail, eliminating downtime.
But there are drawbacks to this system. Because almost all the disks in the array are installed at the same time, the wear and tear on the hardware is uniform. Therefore, if one disk fails, it is likely that the other disks will soon fail as well. RAID is also a more expensive solution than single-disk storage systems. However, cost is an issue for any system with redundant resources.
Performance and Security Issues in Fault Tolerant Systems

Although fault tolerant systems are designed to continue operating in the event of a failure, they can have a negative impact on overall system performance. Redundancy, fault detection, and failover systems add resource costs that can result in reduced throughput. In this case, fault tolerance and performance must be carefully balanced.
Fault tolerant systems often rely on complex software algorithms and protocols to detect and recover from failures. In addition, the interaction between different software components in fault tolerant systems can lead to a complex troubleshooting process. This consumes not only software and hardware resources, but also time.
The performance and security of fault tolerant systems are affected by the complexity of their design. For example, fault tolerance becomes much more complex in distributed systems that span multiple data centers in different geographic locations due to factors such as network latency and synchronization.
Because a fault tolerant system keeps all components up and running and ensures that they are properly designed, it helps prevent security breaches. However, this only works for systems that are properly designed and maintained. An attacker can quickly disable a carelessly designed system, costing you money, customers, and trust.
Conclusion
By building fault tolerant systems, organizations can minimize downtime, ensure business continuity, and provide reliable services to their users or customers. Fault tolerance is especially important for mission-critical systems such as data centers, cloud computing environments, financial institutions, telecommunications networks, and other applications where business continuity is critical.
Now you now what ‘fault tolerant’ means. Build a server infrastructure for your project that is resilient to outages and component failures. Just start by choosing the right server configuration and locations.
VPS
Choose the suitable configuration and enjoy all the benefits of a virtual private server.
From $5.00/mo

