
Полная неуязвимость в self-hosting — это миф. Можно закрутить все фаерволы, раздать ключи SSH и спрятать сервер за дюжиной прокси — ландшафт угроз все равно движется быстрее ваших патчей.
Если стратегия сводится к «держим дверь закрытой», вы готовите себе паническую ночь в воскресенье в 03:00. Настоящая безопасность сводится к тому, как быстро вы встаете, когда в стене появилась трещина, а не в высоте этой стены.
Тут нам ближе отношение к self‑hosted‑безопасности как к системе, которая умеет принять удар, локализовать ущерб и продолжать работать. Или как минимум быстро подняться без потери данных.
Состояние безопасности в self‑hosted‑средах
Здесь мы имеем в виду суммарное состояние вашей инфраструктуры: сети, контейнеры, бэкапы и моральная готовность действовать при инциденте.
В чем суть современного состояния безопасности?
Ресурсы конечны, вы не Google и, скорее всего, у вас нет круглосуточного SOC. В self‑hosted‑средах безопасность определяют видимость проблемы и скорость реакции. Если вы не видите текущее состояние сервера, состояние безопасности у вас слабое. Если не знаете, какой контейнер имеет запись на FS хоста, — тоже.
В идеале нужно сменить вопрос с «мы в безопасности?» на «насколько мы готовы сейчас?».
Типичные слабые места self-hosted инфрастуктур
Свобода self‑hosting’а в том, что можно собрать все, что угодно. И с тем же успехом заиметь уязвимость.
Первое, на что стоит обратить внимание, это базовая изоляция (как бы легко это не звучало). Например, маппят корень в контейнер чтобы было удобнее, держат весь стек в плоской сети, где компрометация одного веб‑сервиса открывает дорогу к БД и серверу с бэкапами.
Другая проблема — alert-усталость. Когда мониторинг шлет сотни мелких предупреждений, реальная проблема может затеряться в этом шуме.
Киберустойчивость как стратегия
Оборонительная стратегия пытается предотвратить событие. Устойчивость исходит из того, что оно случится, и фокусируется на выживаемости.
Базовые принципы киберустойчивости
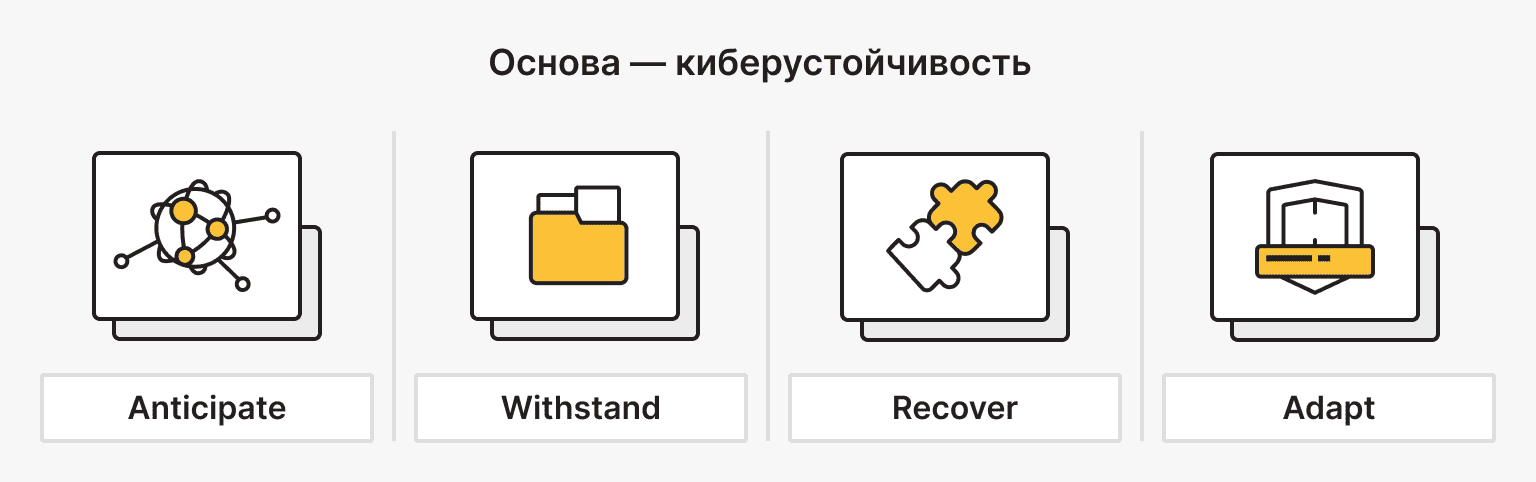
Правильная система безопасности масштабируется от корпораций до одного VPS или домашней лаборатории. Принципы просты: предвидеть (Anticipate), выдерживать (Withstand), восстанавливаться (Recover), адаптироваться (Adapt).
- Anticipate — предвидеть. Знайте свои активы. Нельзя защитить БД, о которой вы забыли три месяца назад.
- Withstand — выдерживать. Система должна деградировать управляемо. Если фронт ловит DDoS, административный API остается доступен через VPN.
- Recover — восстанавливаться. За сколько вы сожжете скомпрометированный сервер и заново развернете чистый?
- Adapt — адаптироваться. Разбор инцидента должен закалять систему, чтобы это не убило ее в следующий раз.
Как вплести устойчивость в повседневные операции
Реализация киберустойчивости в self‑hosted — это автоматизация механизмов выживания с минимумом политик и максимумом кода. Вместо ручного SSH‑чинения дрейфа конфигурации используем Infrastructure as Code. Если нода ведет себя странно, ее не лечат, а уничтожают и поднимают заново.
То есть вы ежедневно тренируете восстановление системы безопасности, потому что деплой — это и есть восстановление.
Это смещает ваш фокус. Сильная система кибербезопасности превращает потенциальную катастрофу в незначительное неудобство.
Как раз для self-hosting
VPS с бесплатными бэкапами и неограниченной пропускной способностью 1 Gbps на большинстве тарифных планов. Выполняйте полную переустановку системы за несколько минут.
Проектируем архитектуру, которая держит удар
Если строить карточный домик, хватит одного тычка. Если строить как из LEGO, то пара утерянных деталей не обрушит замок.
Начинаем с отказоустойчивости
В устойчивой архитектуре мы исходим из отказов: диски умирают, RAM чудит, баги существуют.
Одним из ключевых принципов является избыточность. Если вы запускаете критически важный сервис, не запускайте один экземпляр. Запустите два за балансировщиком нагрузки. Если вы используете выделенные серверы, рассмотрите возможность использования виртуализации для сегментирования сервисов, а не запускайте их на голом оборудовании.
Другой момент — слабая связанность. Фронт, по возможности, не должен напрямую взаимодействовать с БД; он должен проходить через API. Если фронтенд скомпрометирован, злоумышленнику все равно придется выяснить, как использовать API, что даст вам время. Такая многоуровневая структура является основой отказоустойчивой системной архитектуры.
Уменьшаем радиус поражения
Blast radius — это максимальный ущерб при проникновении. В плоской сети он равен 100%. Поэтому используем сегментацию.
В Docker не складывайте все в default‑bridge, изолируйте стеки. Ниже пример docker-compose.yml, где БД недоступна снаружи; backend‑сеть помечена как internal: true, чтобы даже при ошибке в фаерволе она не ушла в интернет.
version: '3.8'
services: webapp:
image: my-web-app networks:
frontend
backend ports:
- "80:80"
database:
image: postgres:15 networks:
- backend
# Отсутствие портов, открытых для хоста, означает отсутствие внешнего доступа
networks: frontend:
driver: bridge backend:
internal: true
Недавно мы уже рассказывали про то, как работет сетевой мост.
От обнаружения к восстановлению
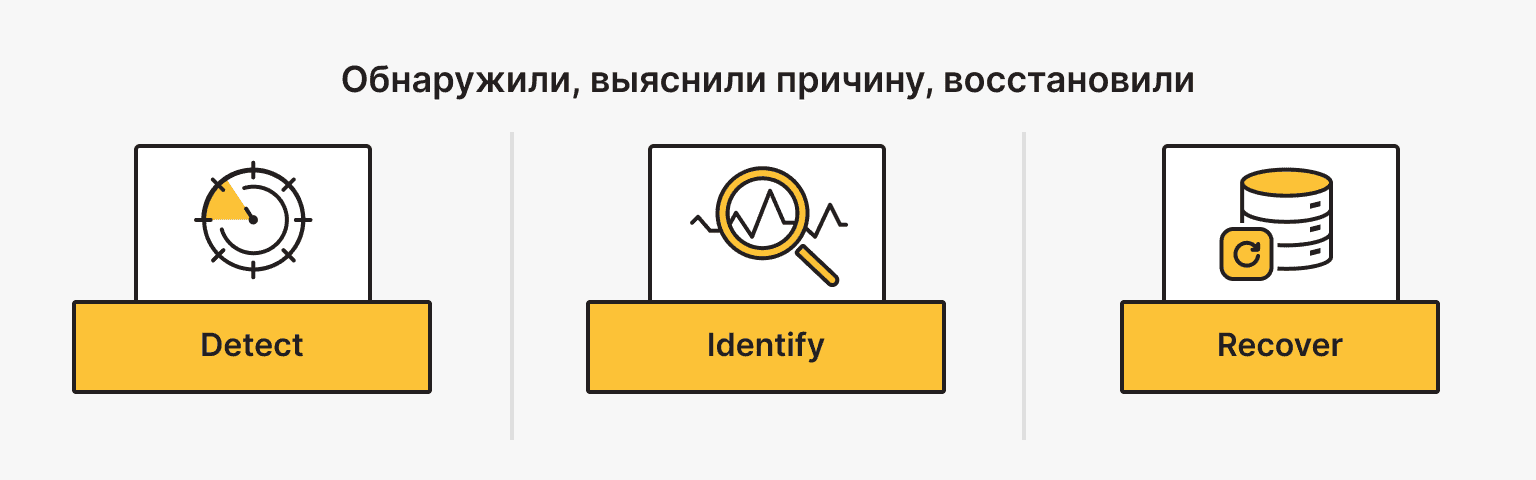
Бороться с невидимой угрозой невозможно. Но детект — это лишь первый шаг. То, запаникуете ли вы или спокойно разрешите ситуацию, решает план реагирования.
План реагирования для self‑hosted
В корпорациях это 50‑страничный том. В вашем случае хватит боевой карточки на одну страницу, которая отвечает на три вопроса:
- Как понять, что нас атакуют? (Alerts)
- Как это остановить? (Containment)
- Как вернуться онлайн? (Recovery)
Оповещения должны быть автоматическими: вам не нужен ручной просмотр логов, нужен сигнал в Telegram, Slack, на почту, например, при пяти неудачных SSH‑логинах за минуту. И инструменты аварийного восстановления (ISO, ключи и т. п.) готовят заранее, а не качают, когда все уже горит.
Базовый workflow восстановления
Когда тревога сработала, вы переходите к восстановлению.
Типовой сценарий:
- Изоляция. Режем сетевой доступ. Не выключаем машину (утратите артефакты в RAM), а выдергиваем виртуальную вилку.
- Триаж. Определяем масштаб: это «скрипт‑кидди» или прицельный эксплойт?
- Очистка. Частая ошибка — закрыть дыру, но оставить следы нападавшего.
- Рестор. Поднимаем сервисы из заведомо чистых бэкапов.
Скомпрометированной машине не верим. Единственный честный путь — wipe & reinstall.
Полезно держать под рукой скрипт экстренной изоляции, который рубит входящий трафик, оставляя доступ только с вашего управляющего IP. Это ощутимо ускоряет работу в пике инцидента.
#!/bin/bash
echo "Locking down server..." MY_IP="192.168.1.50" # Ваш Management IP
# Сброс существующих правил iptables -F
# Установить политики по умолчанию на DROP iptables -P INPUT DROP iptables -P FORWARD DROP iptables -P OUTPUT ACCEPT
# Включить localhost
iptables -A INPUT -i lo -j ACCEPT
# Разрешить установленные соединения
iptables -A INPUT -m conntrack --ctstate ESTABLISHED,RELATED -j ACCEPT
# Разрешить SSH только с MY_IP
iptables -A INPUT -p tcp -s $MY_IP --dport 22 -j ACCEPT
echo "Server isolated. Only $MY_IP has access."
Запуск за 10-15 минут
Протестируйте свои плейбуки на VPS. Развертывание за 10-15 минут, еженедельные бэкапы для отката и встроенный терминал.
Disaster Recovery как часть устойчивости
Disaster recovery — последняя страховка, которая подразумевает худший сценарий. От недоступного дата‑центра до полного удаления данных злоумышленником.
Привязка к бизнес‑эффекту
В self-hosted мире влияние на бизнес может быть и простой вопрос "сколько времени пройдет, пока мой сервер Plex или личная почта не заработают снова". Но принципы восстановления после сбоев остаются прежними.
Определите RPO (сколько данных готовы потерять) и RTO (сколько времени можете быть оффлайн). Делаете бэкап раз в неделю? Значит, фактически теряете неделю данных.
Часто восстановление после инцидента подводят сами бэкапы. Они должны быть зашифрованы, immutable (нельзя изменить или удалить) и air‑gapped (не висят постоянно в той же сети).
Проверка и валидация способности к восстановлению
Бэкап — всего лишь теоретический файл, пока вы его не восстановили. Раз в квартал поднимайте сервис из бэкапа в тестовой среде. Если не вышло, то ваша стратегия восстановления не работает.
Еще полезно помнить правило 3‑2‑1 в трактовке CISA.
Проактивные меры и снижение рисков

Ждать атаки — это проигрышная стратегия. Принимайте проактивные меры для выявления проблем безопасности до того, как они приведут к нарушениям.
Непрерывная оценка рисков безопасности
Регулярно гоняйте сканеры уязвимостей (OpenVAS, даже простой Nmap), смотрите на инфраструктуру глазами атакующего.
Проверяйте системы на отклонения в конфигурации. Кто-то временно открыл порт 8080 для тестирования и забыл его закрыть? Желательно проверять это чаще чем раз в месяц.
Внедрение проактивных мер безопасности
Как сделать проактивные меры безопасности частью вашей повседневной работы, чтобы они не превратились в рутинную обязанность? Автоматизируйте их.
Настройте автоматические обновления для патчей безопасности. Да, обновление может иногда что-то сломать, но незапатченный сервер в конечном итоге будет взломан.
Удалите программное обеспечение, которое вы не используете. Если вам не нужен компилятор на веб-сервере, удалите его. Это укрепит вашу систему управления безопасностью, ограничив инструменты, доступные злоумышленнику в случае взлома.
Внедрите модель минимальных привилегий. Действительно ли вашему медиасерверу нужен root-доступ? Вероятно, нет.
Вот фрагмент кода для проверки пользователей с UID 0, который указывает на root-привилегии.
awk -F: '($3 == 0) {print}' /etc/passwd
Если в выводе есть кто‑то, кроме root, — это проблема.
Как измерять и развивать состояние безопасности
Считайте сколько инцидентов ловите, как быстро закрываете критичные уязвимости, сколько времени уходит на пересборку с нуля.
При появлении новых угроз оценивайте, достаточно ли у вас видимости и не сменила ли архитектура статус от изначально устойчивой к удобной, но хрупкой.
Ваша система кибербезопасности должна развиваться. Когда появляется новая угроза, оцените, как с ней справляется ваша текущая система управления безопасностью. Можно ли увидеть, как вы затронуты этой угрозой.
Заключение: устойчивость после инцидента важнее отсутствия инцидентов
Мы не хотим вызвать у вас паранойю, а лишь подготовить вас. Сосредоточившись на self-hosted безопасности через призму отказоустойчивости, вы перестанете бояться взлома и начнете управлять рисками.
В конечном счете self-hosted безопасность сводится к определенному образу мышления. Речь идет об использовании проактивных мер, чтобы вы могли спать спокойно, зная, что даже если произойдет худшее, у вас есть система управления безопасностью, которая справится с этой ситуацией.
Сделайте систему безопасной. Поломайте ее сами. Исправьте. Так рождается настоящая устойчивость.
Bare Metal
100% ресурсов в вашем распоряжении. Для требовательных рабочих нагрузок и кастомных настроек.
От $66.67/месяц

