
The growing complexity of artificial intelligence and machine learning has driven an increasing demand for more powerful machines. Deep learning, in particular, requires significant processing power to handle large datasets and intricate algorithms. One cost-effective solution is building your own deep learning server from scratch, offering both customization and savings compared to pre-built options.
Keep reading this article to discover how to create a deep learning server tailored to your specific needs.
Deep Learning Server Requirements

Choosing the right hardware components is the foundation of building a deep learning server. Each piece is important in how well your system performs overall and how easy it is to expand.
CPU vs. GPU
Before learning to create a deep learning server, it’s essential to understand the roles of the CPU and GPU. Both are useful, but they are better suited for different types of computing tasks.
The Central Processing Unit (CPU) in a deep learning server handles tasks such as data preprocessing, GPU coordination, and input/output operations. A CPU with multiple cores and high clock speeds is crucial for managing these tasks efficiently. Processors like the Intel Core i9 or AMD Ryzen 9 series are great for deep learning applications because they offer a strong balance of performance and affordability.
The Graphics Processing Unit (GPU) is the powerhouse for deep learning computations. GPUs excel at parallel processing, making them ideal for training complex neural networks. They handle the heavy lifting of mathematical computations, significantly reducing training times. NVIDIA's RTX and A100 series are among the best GPU servers for deep learning, offering a large number of CUDA cores, substantial VRAM, and Tensor Cores that accelerate tensor computations.
RAM
Random Access Memory (RAM) provides temporary storage for data that the CPU and GPU need to access quickly. Adequate RAM is essential for smooth operation during data-intensive tasks. 32GB is typically sufficient for basic deep learning projects, but larger datasets and more complex models may require 64GB or even 128GB.
While capacity matters most, faster RAM can offer a slight performance boost. Using DDR4 with speeds of 3200MHz or higher is recommended. Be sure to check compatibility with your motherboard manufacturer to ensure optimal performance and data management.
Storage
A good storage system is also essential for managing large datasets, storing models, and ensuring quick data access. Solid State Drives (SSDs) deliver much faster read/write speeds compared to traditional Hard Disk Drives (HDDs), making them ideal for the operating system and active projects. For less frequently accessed data, HDDs are a cost-effective option for archival storage.
Deep learning tasks often require significant storage capacity. A balanced setup typically includes a high-capacity SSD (1TB or more) for active data and an HDD (4TB or more) for backups and bulk storage, offering a practical combination of speed and capacity.
This ideal solution for large-scale projects offers unbeatable protection, high performance, and flexible settings.
Motherboard and Power Supply
The motherboard and power supply unit (PSU) are critical for ensuring your hardware operates reliably and efficiently. When selecting a motherboard, make sure it's compatible with your CPU, has enough PCIe slots for GPUs, and supports the RAM you need. Features like M.2 slots for NVMe SSDs and solid VRM designs boost performance and simplify future upgrades.
For the PSU, prioritize stable power delivery. Calculate your system's total wattage requirements and choose a PSU with at least 20% additional capacity to handle upgrades and power surges. An 80 Plus Gold efficiency rating or higher is recommended for reliability and energy efficiency.
Cooling Systems
Effective cooling prevents thermal throttling, maintains optimal temperatures, and extends component lifespan.
Air cooling with fans and heat sinks is a cost-effective solution suitable for moderate setups. Liquid cooling is more complex and costly, but it provides superior thermal management for servers with multiple GPUs or heavy workloads, making it ideal for high-performance deep learning systems.
Choosing the Right GPU

Choosing the right GPU server for deep learning is one of the most important steps. The GPU determines how quickly models can be trained and how effectively the server handles large datasets and complex neural networks.
Key Factors: VRAM, CUDA Cores, Tensor Cores
Choosing a GPU with the right specifications directly impacts the speed of training, the complexity of models you can work with, and overall performance in deep learning tasks. Pay close attention to the following factors in particular:
- VRAM (Video RAM) determines the size of models and batch sizes a GPU can handle. Higher VRAM enables processing larger datasets and more complex models. At least 12GB is recommended for most deep learning applications.
- CUDA Cores are NVIDIA's parallel processors designed for handling complex computations. A greater number of CUDA cores enhances the GPU's ability to perform simultaneous calculations, improving performance.
- Tensor Cores, available in NVIDIA's RTX and A100 series, accelarate tensor operations critical for deep learning. They are especially useful for mixed-precision training, which balances speed and accuracy.
Best GPU for Deep Learning
The following GPUs are popular choices in the deep learning community:
- NVIDIA RTX Series. The RTX 3080 and RTX 3090 are widely used among researchers and enthusiasts. The RTX 3090, with 24GB of VRAM, is ideal for handling large models and datasets. These GPUs offer excellent performance for their price and support advanced features like Ray Tracing and DLSS.
- NVIDIA A100. Designed to handle big data and complex apps, the A100 delivers exceptional performance with up to 80GB of VRAM. It's perfect for large-scale deep learning projects. However, its high cost makes it best suited for companies with bigger budgets.
- NVIDIA Tesla Series. The Tesla V100 and P100 are professional-grade NVIDIA GPU servers known for their high reliability and performance. They are excellent choices for computational tasks and enterprise-level apps.
Assembling the Deep Learning Server
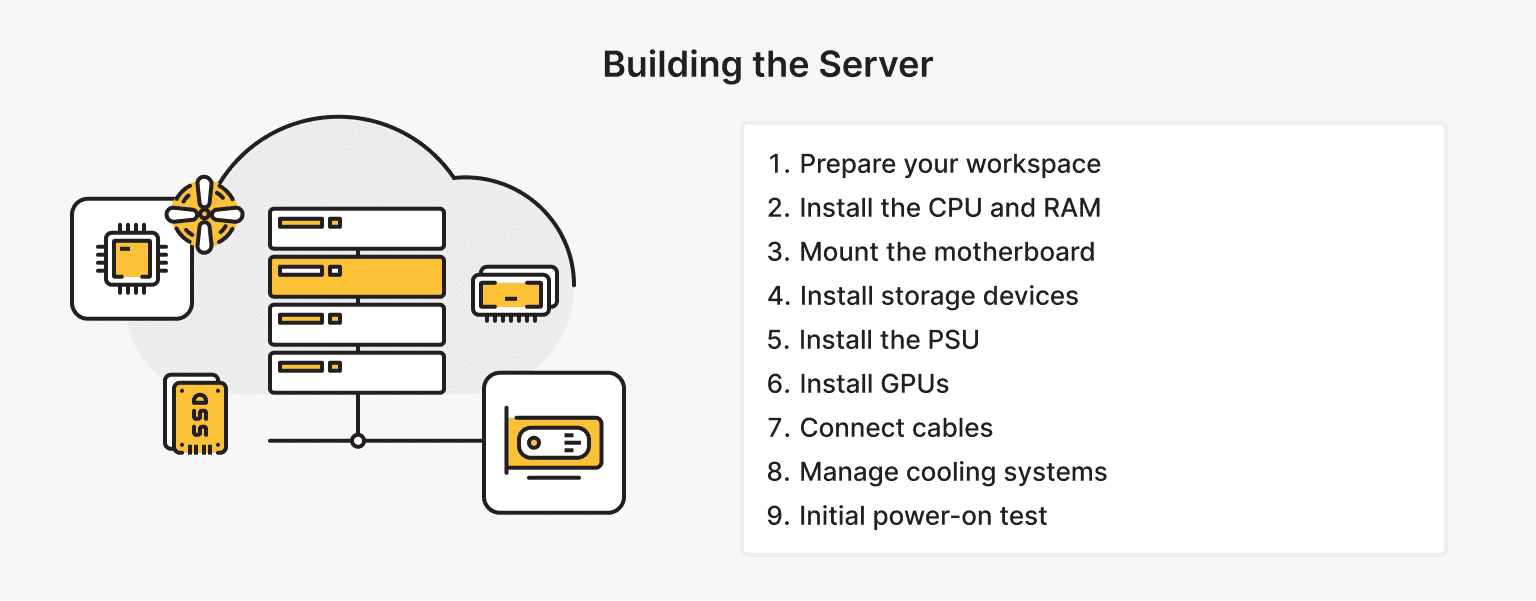
Once all the components are in place, it’s time to assemble your machine learning server:
- Prepare your workspace. Set up a clean, static-free workspace with ample lighting. Gather the required tools, like screwdrivers and an anti-static wrist strap, to protect components from static electricity damage.
- Install the CPU and RAM. Carefully place the CPU into the motherboard socket, aligning the notches. Apply thermal paste and attach the CPU cooler securely. Install the RAM modules into the recommended slots for dual or quad-channel operation.
- Mount the motherboard. Secure the motherboard to the case using standoffs to avoid electrical shorts. Ensure that all ports align properly with the case's I/O shield for proper connectivity.
- Install storage devices. Mount the SSDs and HDDs into their respective bays, connecting them to the motherboard via SATA cables or M.2 slots for NVMe SSDs.
- Install the PSU. Place the PSU into the case, tiypically at the bottom or top, based on the case’s design. Carefully route power cables to the motherboard, CPU, GPUs, and storage devices.
- Install GPUs. Insert the GPUs into the PCIe slots, securing them with screws. Connect power cables from the PSU to each GPU.
- Connect cables. Attach all necessary cables, including SATA cables for storage devices and front panel connectors for power and reset buttons. Organize the cables to improve airflow.
- Manage cooling systems. Install case fans or liquid cooling components. Make sure airflow is optimized, with intake fans pulling cool air in and exhaust fans pushing hot air out.
- Initial power-on test. Before closing the case, perform a test boot to ensure all components are recognized and the system successfully passes the Power-On Self-Test (POST).
Maximize your budget with our high-performance VPS solutions. Enjoy fast NVMe, global reach in over 35 countries, and other benefits.
Software Setup
After assembling the hardware, setting up the software environment is crucial to leverage your artificial intelligence server’s capabilities.
Operating System
The operating system you choose affects how well your deep learning frameworks and hardware drivers work together and how quickly they perform. For deep learning AI servers, Linux remains the top choice due to its stability, efficiency, and strong support ecosystem. Among Linux distributions, Ubuntu LTS versions are particularly favored for their user-friendly interface and active community, while CentOS and Debian are known for their reliability and robustness in high-demand environments.
Although Windows is less commonly used for deep learning, it may be suitable for specific applications. The Windows Subsystem for Linux (WSL) provides access to Linux tools within the Windows environment. However, this setup can add complexity and is generally less efficient than a native Linux installation for deep learning tasks.
Deep Learning Frameworks
Installing the appropriate frameworks enables you to build, train, and deploy deep learning models effectively. Each framework has its own unique features. For instance, TensorFlow is very versatile, PyTorch is great for experimentation, and Keras is simple to use.
Installing Essential Libraries
To make the most of GPU acceleration with your deep learning frameworks, installing the right libraries is crucial:
- CUDA. Download and install the CUDA Toolkit from NVIDIA's website, ensuring it’s compatible with your GPU and deep learning frameworks. CUDA enables GPU acceleration for computations.
- cuDNN. Register on NVIDIA's developer website, then download and install cuDNN. It accelerates deep learning computations, providing significant performance improvements in training models.
- Python. Install Python 3.x, preferably the latest stable release. Use package managers like apt or yum on Linux, or download it directly from the official website. Python is the primary language used in deep learning frameworks.
Setting Up Virtual Environments for Package Management
Isolating project dependencies with virtual environments helps ensure that libraries and configurations specific to one deep learning project don’t interfere with others. Anaconda, a widely used distribution, simplifies package management and deployment with its built-in tool, conda. This package manager allows you to create isolated environments tailored to individual projects, making it a versatile choice for users working on multiple tasks simultaneously.
For those seeking a more lightweight option, virtualenv offers an alternative. It lets you create isolated Python environments with minimal overhead, making it ideal for users who prefer a streamlined setup and greater control over the specific packages they need.
Network Configuration

Properly configuring network settings ensures reliable remote access, secure data transfers, and protection against unauthorized access to your server. Important settings to configure include:
- SSH access. Setting up Secure Shell (SSH) enables remote server access. Install and configure OpenSSH server, and consider using key-based authentication for added security.
- Firewall settings. Protect your server from unauthorized access by configuring a firewall. Tools like UFW (Uncomplicated Firewall) on Ubuntu simplify managing firewall rules to enhance security.
- Data transfer protocols. For transferring large datasets, use secure protocols such as SCP (Secure Copy Protocol) or SFTP (Secure File Transfer Protocol). Consider setting up FTP servers with SSL/TLS encryption for convenience and security.
Performance Optimization
Optimizing your server for deep learning allows you to maximize the return on your hardware investment. Both hardware and software optimizations can lead to significant performance improvements:
- GPU overclocking. If your hardware supports it, overclocking GPUs can boost performance. Use tools like NVIDIA's System Management Interface (nvidia-smi) to adjust settings carefully and monitor temperatures to prevent overheating.
- Software tweaks. Optimize deep learning frameworks by adjusting parameters such as batch size, learning rate, and precision settings. Mixed-precision training can accelerate computations while maintaining model accuracy.
- Monitoring tools. Set up monitoring tools like Prometheus and Grafana to track system metrics. Monitoring allows you to identify where things are slowing down and ensures efficient resource use.
- Code optimization. Profile your code to find inefficiencies. Use optimized libraries and functions, and minimize data transfers between CPU and GPU to further enhance performance.
Testing the Deep Learning Server

Before deploying your deep learning server in production, test it’s crucial to test its performance thoroughly. Start by benchmarking to evaluate how your CPU, GPU, memory, and storage perform under normal conditions. Tools like Geekbench or Phoronix Test Suite can help compare your results against expected benchmarks to identify potential issues and ensure the system meets performance standards.
Next, conduct stress tests to assess system stability under heavy workloads. Tools like stress-ng for CPU and RAM or FurMark for GPU can simulate high-demand scenarios to test how well your system handles them.
To ensure your deep learning frameworks set up properly, run sample training sessions on datasets like MNIST or CIFAR-10. If you've successfully trained these models, your server is ready to handle computational workloads effectively and without errors.
During testing, monitor resource usage to ensure hardware components are being utilized efficiently. Adjust configurations if necessary to prevent bottlenecks and maintain smooth performance.
is*hosting is always ready to help. Ask questions or contact us with problems — we will definitely answer.
Maintenance and Upgrades
Maintain your machine learning server to keep it running smoothly and ensure its longevity. Schedule software updates for the operating system, drivers, and frameworks to access new features and security fixes. Periodically check the hardware, clean dust from cooling components, and replace any damaged parts.
Monitoring tools like Prometheus and Grafana privide real-time insights, allowing you to spot problems early. Plan for upgrades, such as adding GPUs or increasing memory, to accommodate growing demands and maintain your server's performance for deep learning tasks.
Conclusion
Building a deep learning server from scratch is both practical and rewarding. It allows you to tailor the hardware and software to your exact requirements, often offering better performance and cost efficiency compared to pre-built options. With a bit of planning and the right components, you can build a system optimized for handling the demanding workloads of deep learning.
This guide has outlined every step, from hardware selection and assembly to server configuration for deep learning and performance optimization. Whether you're a researcher, developer, or AI enthusiast, this investment provides a powerful tool to advance your deep learning projects and achieve superior results.
Dedicated Server
Smooth operation, high performance, and user-friendly setup - it's all there for you.
From $70.00/mo

