Сумеют ли нейросети создавать полноценный творческий контент, или им не заменить человека? Это – главная интрига с тех пор, как начались эксперименты по обучению ИИ работе с человеческой речью, как устной, так и письменной.
Нейросеть BERT и GPT нейросеть: их цели и истории создания
С 2017 года корпорация Google развивает проект Transformers, ориентированный на создание нейронной сети, понимающей естественную речь. В середине 2018 года исследовательская компания OpenAI, одним из основателей которой выступил Илон Маск, представила нейросеть GPT на архитектуре Transformers, предобученную при помощи гигабайтов текста. Как выяснилось, подобная специализация резко повышает state-of-the-art - уровень развития сети.
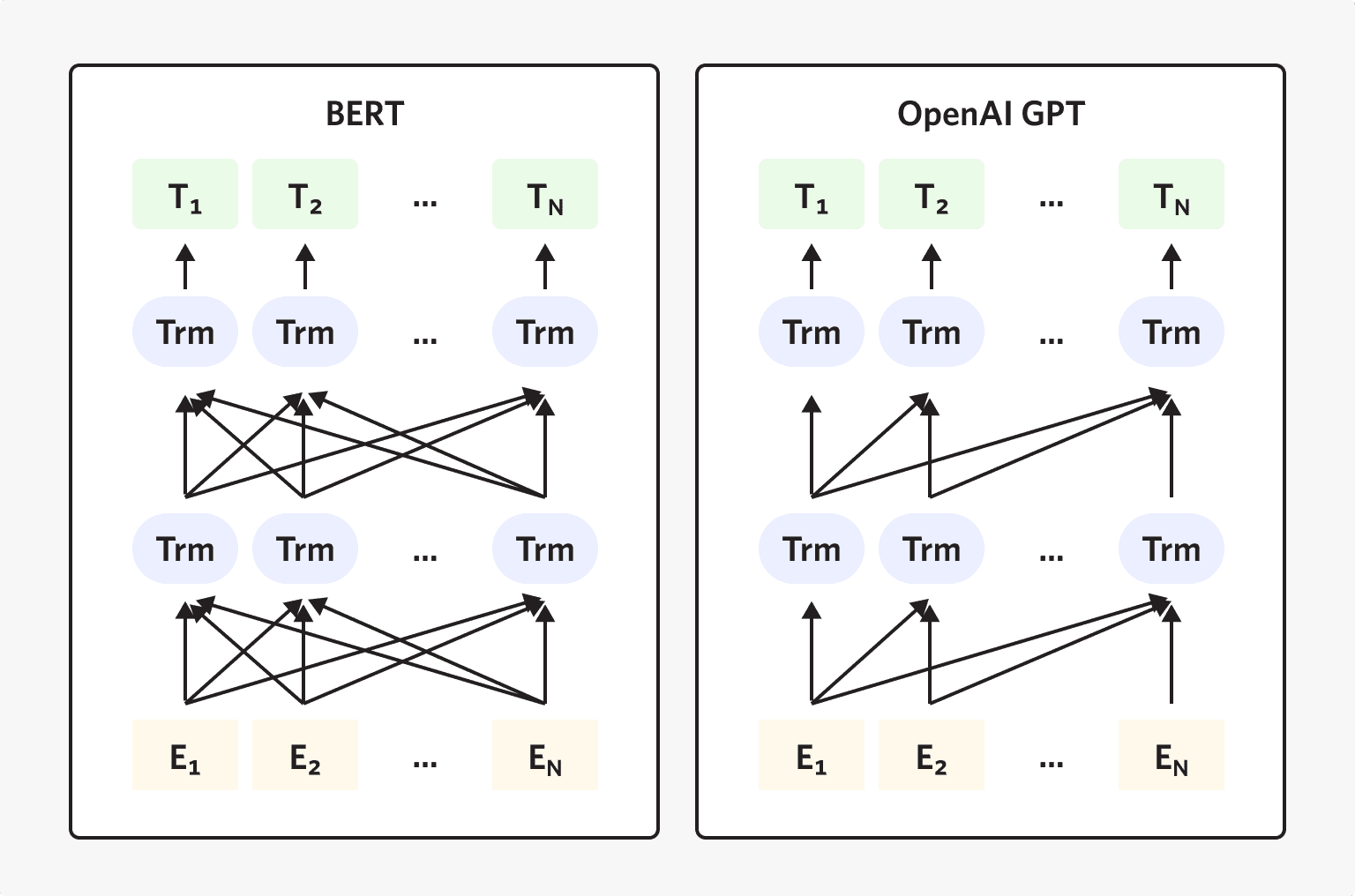
К концу 2018 года Google построила новый поисковый алгоритм на базе собственной двунаправленной нейросети BERT. Её основная задача – понимать запросы на естественном языке и формировать подсказки в соответствии с контекстом. OpenAI приняла вызов и резко увеличила объём обучающего текста, доведя его до 40 Гбайт. В результате появилась крупнейшая в мире нейросеть GPT-2 с 1,5 млрд параметров. Для сравнения: у самой крупной реализации сети BERT их всего 340 млн.
Нейросеть GPT-2 имела первоначальной целью предсказание следующего слова на основании предыдущих в заданном тексте. Поначалу для обучения нейросетей использовались статьи Википедии и аналогичные источники, но результат не удовлетворил разработчиков: сети, обученные подобным образом, текст генерируют плохо. Разнообразить контент для обучения удалось с помощью свободной выборки из интернета, используя только страницы сайтов, к которым проявляли интерес пользователи, имеющие не менее трёх отзывов.
Предобученная нейросеть способна не только понимать естественный язык, но и формировать массивы связного текста с упоминанием разных действующих лиц, цитатами, датами связанных событий, ссылками на близкие по содержанию материалы. Это впечатляющее достижение, и нейросеть GPT-2 способна показать результаты во множестве областей знаний.
Алгоритм BERT работает иначе. Он предсказывает не следующее, а пропущенное слово в запросе. И выясняет логическую связь двух стоящих рядом предложений, то есть понимает смысл фраз в зависимости от контекста. Но всё это – только после дополнительного обучения для конкретной задачи. А вот GPT-2 в дообучении не нуждается, ей достаточно начала текста, чтобы самостоятельно его продолжить.
Результат первых испытаний оказался настолько впечатляющим, что OpenAI не стала публиковать исходники, нарушив собственную политику приверженности принципам открытого кода. Возникли опасения, что нейросеть GPT-2 будет использована для создания фейковых новостей и распространения ложной информации, поэтому сперва был выпущен её упрощённый вариант.
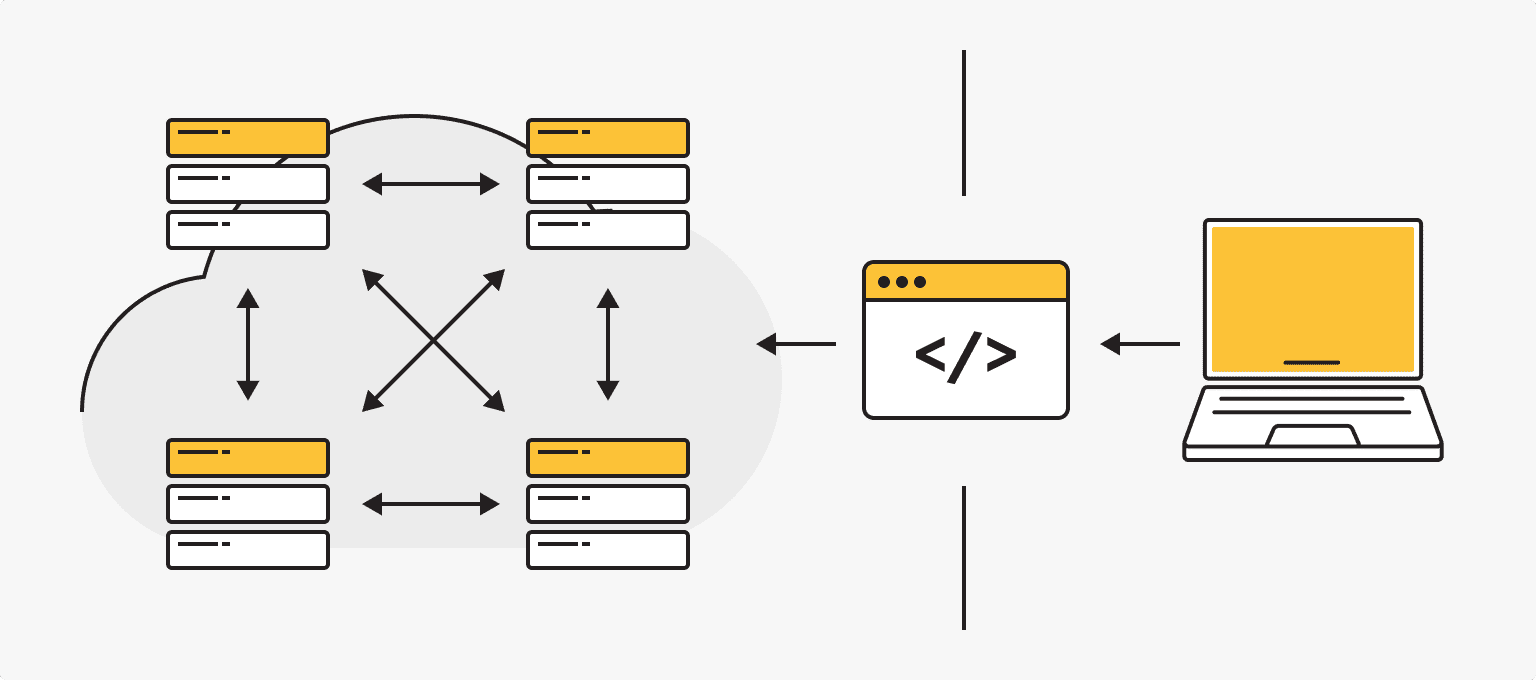
Весной 2020 года исследовательской группой из Uber совместно с ведущим исследователем OpenAI был представлен фреймворк Fiber (framework – платформа, объединяющая компонеты и части программного обеспечения в единый комбайн), предназначенный для эффективного распределённого обучения AI-моделей. Он совместим с Linux и с последними версиями языка Python. Fiber распределяет нагрузку на сотни серверов, поэтому параллельные вычисления не требуют дополнительного оборудования.
Исходный код Fiber выложен на Github. Создан специальный сайт, где все желающие могут экспериментировать с нейросетью GPT-2 в режиме веб-страницы. Нет сомнений, что коллективные усилия разработчиков всего мира быстро найдут решения выявленных в процессе работы проблем. Одна из них – недостаточный уровень предобучения на языках восточно-славянской группы, однако и здесь уже есть заметные сдвиги.
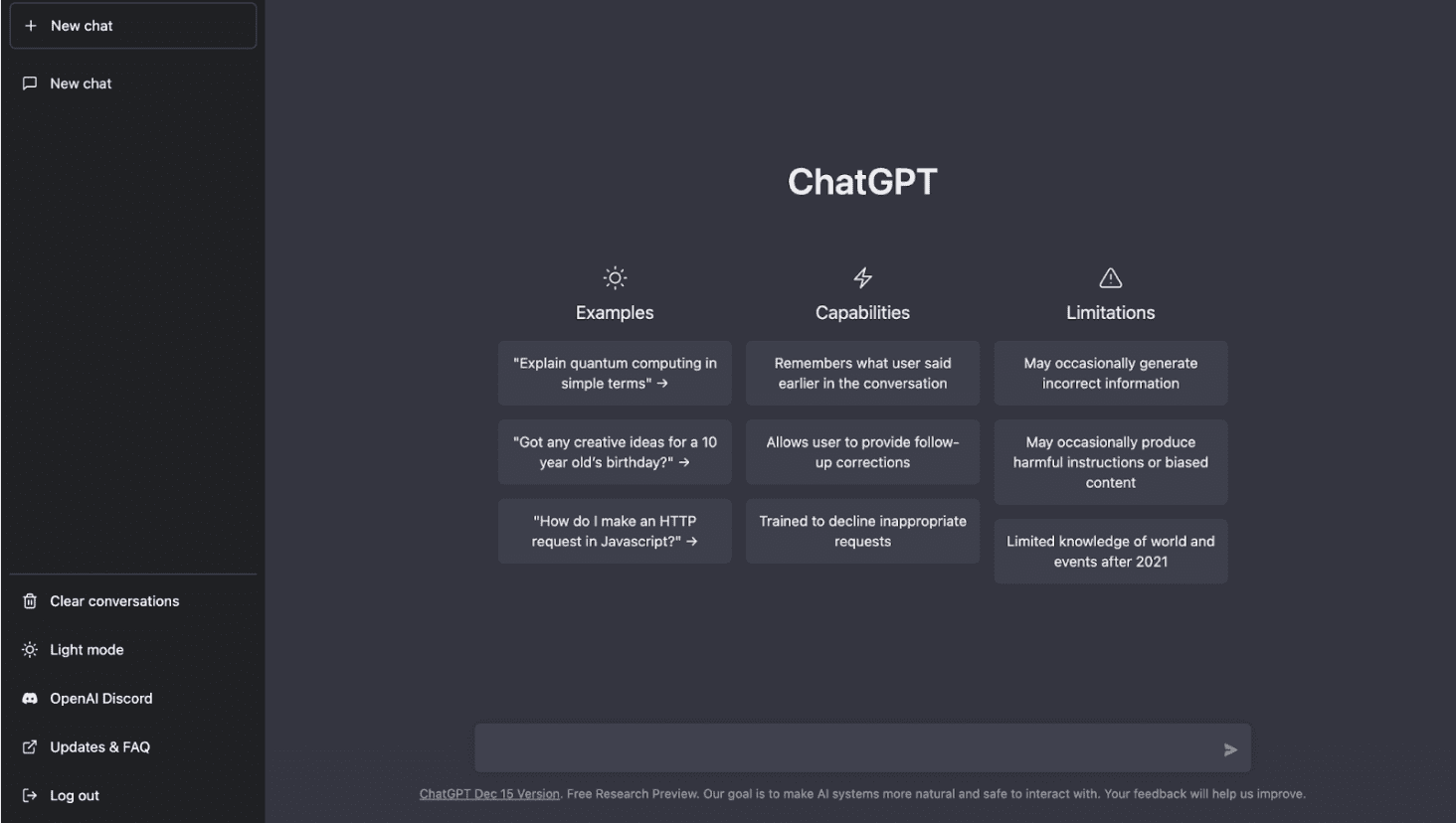
Пример “подручного” использования искусственного интеллекта - чаты chat.openai.com. ChatGPT создан на основе GPT-3.5, языковой модели, обученной для создания текста, и оптимизирован с помощью Reinforcement Learning with Human Feedback (RLHF), что позволяет направлять модель к желаемому поведению. Общаться с нейросетью можно сообщениями на любую тематику: от объяснения сложных научных понятий до идей подарков ребенку. ChatGPT запоминает предыдущие запросы пользователя, позволяет их изменять и способен отклонить неуместные вопросы.
Однако и здесь по-прежнему есть ограничения: сеть имеет ограниченные знания о мире после 2021 года, может выдать предвзятую или некорректную информацию. Также ChatGPT все еще находится в процессе улучшений, поэтому все разговоры пользователей с ИИ могут быть просмотрены и проверены на соответствие политикам и правилам безопасности.
Голос русскоязычных нейросетей
Яндекс внедряет нейросети в свои поисковые алгоритмы с 2017 года, и поначалу этот процесс ограничивался музыкой, картинками и объектами нейроискусства. В 2018 году нейросеть Яндекса «прочла» 30 тысяч книг русскоязычной прозы, затем её дообучили с помощью полного собрания сочинений Н.В. Гоголя.
Один из российских писателей-фантастов задал сюжетную канву, и нейросеть создала на её основе рассказ «Дурной договор». Текст стилизован под рассказы из цикла «Вечера на хуторе близ Диканьки» и, по отзывам аудитории, гоголевский стиль оказался полностью соблюден. Проект создавался в партнёрстве с телеканалом ТВ-3, рассказ опубликовали накануне премьеры фильма «Гоголь. Страшная месть». Литератор, ведущий этот проект, заявил, что некоторые современные книги заметно уступают творению нейросети, однако всё же ей необходим первоначальный сюжет или синопсис, заданный человеком.
Нейросеть Порфирьевич и Нейропоэт
Впечатляет нейросеть Порфирьевич Бот и ее алгоритм, созданный московским программистом Михаилом Гранкиным, – аналог Chat GPT-2, предобученный на произведениях классиков русской литературы. Имя нейросети дал «полицейско-литературный» робот из романа Виктора Пелевина «iPhuck», изданного в 2017 году.
Работать с «Порфирьевичем» можно через браузер, достаточно ввести начало текста, и нейросеть его дополнит. Результат получается осмысленный, но совершенно непредсказуемый. Также, например, создать новое стихотворение можно через telegram-бот «Нейропоэт». Его запустил на базе «Порфирьевича» украинский разработчик Юрий Лу.
Эксперименты в областях лингвистических нейронных сетей могут казаться еще незрелыми. Но они неуклонно приближают момент, когда люди смогут полноценно общаться с синтетическими компьютерными интерфейсами на естественном языке.